
LLMのモデルサイズが64GBもある4bit量子化版Command R+ 104B版の動作が遅い。インテル Core i7 12700H(Alder Lake)というiGPUだから、共有メモリの関係などで仕方ないのかもしれない。
そこで今回は全てをVRAMにオフロードできる5GB程度の4bit量子化版7B版のLLMを実行してみた。結論から言うと、「普通に何もせずにmakeしたCPUオンリーに比べて体感2倍程度の遅さ」という状況である。
いくらIntel Iris Xe Graphicsドライバで動作していても、実行ユニット数は何とか96で、GPUメモリは相変わらずCPUメモリと共有。僕も適当に作業したので、警告メッセージが頻繁に表示された状態でのコンパイル完了となった。正直言って、無事に応答(生成)されているだけでも感動している。
そんな訳で検証作業の途中段階に過ぎないけれども、後進のために記録として残しておくことにする。
CPUのみ
BLAS = 0 と表示されているように、Llama.cpp実行時にGPUは使用されていない。
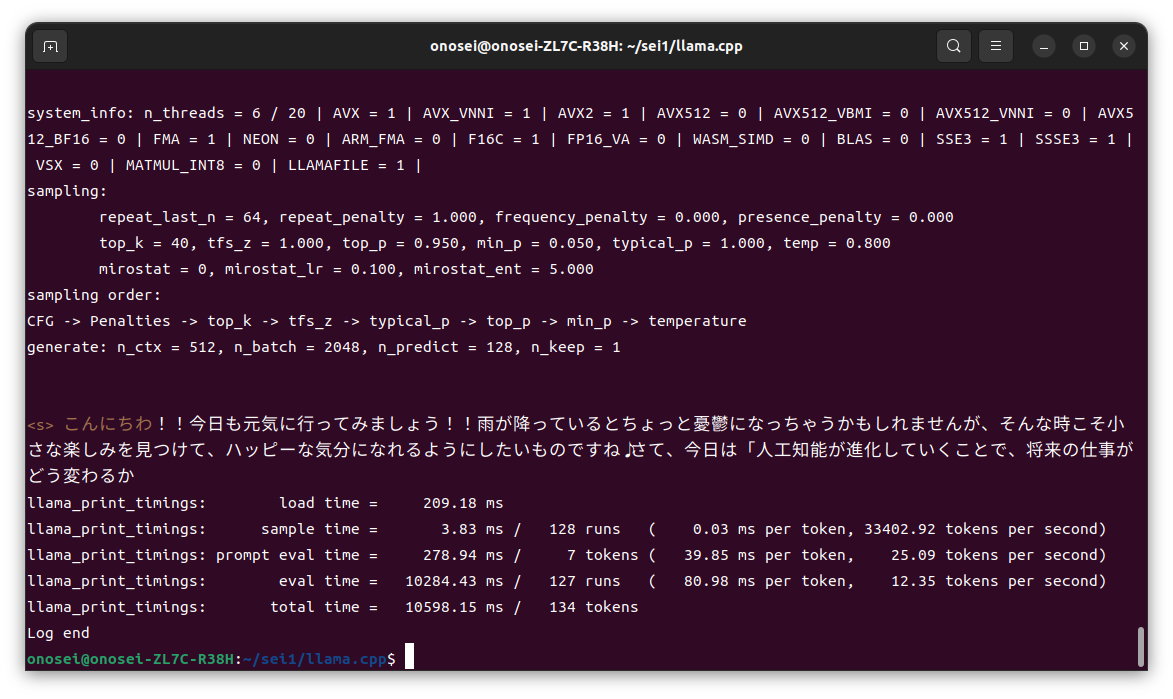
ちなみに実行したコマンドは、下記の通り。
./main -m ./models/DataPilot-ArrowPro-7B-KUJIRA-Q4_K_M.gguf -p “こんにちわ” –color -n 128 -e
NPUを利用
BLAS = 0 と表示されているように、Llama.cpp実行時にNPU?を使用している。
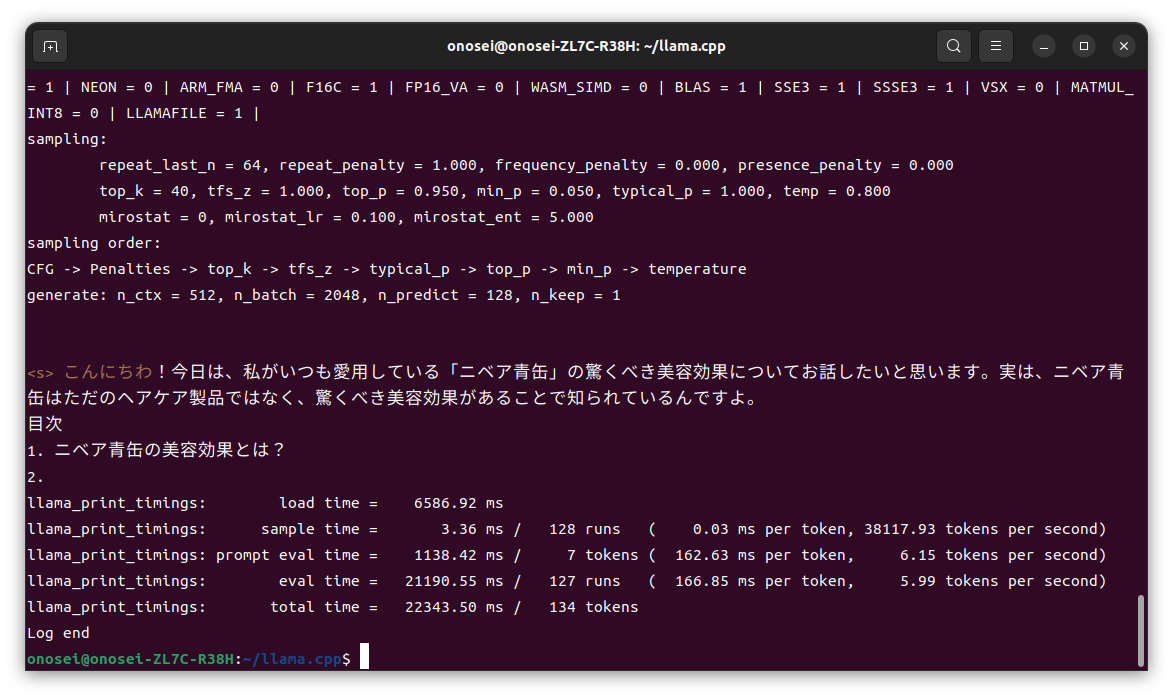
ちなみに実行したコマンドは、下記の通り。
ZES_ENABLE_SYSMAN=1 ./build/bin/main -m ./models/DataPilot-ArrowPro-7B-KUJIRA-Q4_K_M.gguf -p “こんにちわ” –color -n 128 -e -ngl 35 -sm layer
まとめ
7B版LLMは35層構成なので、これで全てVRAMへオフロードできている(ハズ)である。その結果は数字を見ると、体感と同じく約2倍の出力(推論)時間を費やしている。
これがモバイル版Alder Lakeの限界なのか、はたまた僕の設定や作業内容がヘボいのかは不明。とりあえずIntel Arc A770が到着したので、まずはそちらで検証を進めてみる予定。


それでは今回は、この辺で。ではまた。
------
記事作成:小野谷静(オノセー)




