
さてインテルCore i7 12700H(Alder Lake)のiGPUを使って、無事かは不明だけれどもLlama.cppを動かすことには成功した。そこで次段階として、Intel製GPUであるIntel ARC A770でLlama.cppを動かしてみることにした。VRAMはコンシューマー向けでは最大の16GBである。くくく… 謎の含み笑い。
ちなみに残念ながら、Intel純正品ではない。予算の都合で、安かったASRockのOEM製品である。10年前のDeep Learning時代からお世話になっているドスパラさんが格安販売していたのである。


なんでも半年前くらいは16GB版が29,800円だったという情報が価格コムに掲載されているが、今では中古品でさえ、そんな価格では調達困難だ。年末からドライバの品質が向上し、ゲームでも結構使いものになると評判が上がって来た。そしてoneAPIもリビジョンアップが進み、とうとう3月半ば頃からPytorch、transformers、Llama.cpp for SYCLといったLLM関係者ご用達ツールも充実して来た。
多分もう投げ売りは期待できないと思う。そうでなくても1ドル150円というご時世になり、海外ユーザが国内GPUを買い漁っている。今後のIntel GPUビジネス成長に賭けるなら、今が購入タイミングかもしれない。
さて以上のようなGPU販売状況はビジネス的には重要だけれども技術者的には「どーでも良い」話である。さっそく本題に… 本題に… 残念ながら、今回はブログ記事の通りで、「動かしてみた」という程度に過ぎない。
なぜならVRAMにモデルを全てオフロードできる4bit量子化版LLMを動作させることには成功したものの、約64GBサイズの4bit量子化版Command R+ 104B版の稼働には成功していない。6月にはIntel主催のハンズオンを受ける予定なので、せめてそれまでには… という状況である。
なお、ただ「動きました」と出力データを公開するだけでは申し訳ない。今回はiGPUの時よりは詳しく作業手順を紹介させて頂くことにしたい。
動作環境
まず動作環境は次の通りだ。
- インテル Core i5 8500なんたら
- ASRock Z370 Taichi
- メモリ容量:64GB
- SSD:500
- ASRock OEM版 Intel ARC A770
- ビデオメモリ(VRAM):16GB
- 電源:1000Wと750Wの組み合わせ
- 筐体:Deep Silent 5
- OS:Ubuntu 22.04
2014年頃に購入した時はドスパラのガレリアだったけれども、今も使用されているのは電源装置だけだったりする。
Intel ARC A700は見たところ、けっこうゴツい。AIスパコン世界2位のAuroraで採用されているIntel Datacenter Max GPUは見たことがないけれども、もしかしたらNVIDIAみたいに基本アーキテクチャは同じなのかもしれない。
ちなみに電源装置が1000Wと750Wのダブル構成になっているのは、ガレリアの750WではNVIDIA Telsa P40 (Pascaalアーキテクチャ)を動かせなかった為だ。ソイツは8ピンの独立した電源を2系統必要とするので、電源周りは増強せざるを得なかった。このマシンはTelsa P40 GPUを二枚刺しにしてVRAMを48GB化する予定だったので、1000W単独ではなく、1000Wと750Wの同時使用構成にした。

Telsa P40はDC向け… つまりデータセンターで計算処理用に使用される “DC向けGPU” である。冷却ファンなどという軟弱なものは付属しておらず、こちらで冷却機構を装着させる必要がある。消費電力も半端ではなく、だから前述の8ピン2系統が要求されている。
Intel ARC A770は、そういったAIスパコン向けGPUに慣れた僕にとっては、全く違和感のないGPUだ。面倒だから確認しなかったけれども、もしかしたらNVIDIAのGeForceと同じく、非独立な8ピン1系統な電源でも全く問題なく動作するかもしれない。
(つまりドスパラの750W電源だけで、何となく無事に動いてしまいそうな気がしている)
なお現時点で気にしていないのは、Intel ARC A770を二枚刺しにして32GB化するという夢も持っているからだ。幸い我がASrock Z370 TaichiはGPUを二枚刺しにした場合、普通のコンシューマー向けマザーボードとは異なって 8 x 2 構成になってくれる。普通は16 x 1と4 x 1となってデータ転送速度が劇落ちするので、その点は嬉しいマザーボードなのである。
(Supermicroマザーを使って16 x 2接続している強者もいるけど… ま、それはいずれ後また)
なお聞くところによると、Intel ARC A770はNVIDIA Telsa P40などと同様に、Resizable BARとかAbobe 4G Decodingなどの設定が必要になるらしい。最近のマザーボードは「使用する」という設定がデフォルトになっているらしいが、もし順当に動かない場合は、UEFIでハードウェア周りの設定を確認すると良いかもしれない。ちなみに僕がガレリアに付属していたH97マザーボードを卒業したのも、Telsa P40を利用する際に上記設定に対応できない古いマザーボードだったことが原因だ。ここら辺に関してはRedditやNVIDIAのコミュニティ向け掲示板が詳しいので、参考にすることをオススメしたい。(もちろんIntel Communityでも構わないだろうけど、まだ慣れていないので紹介する自信がない)
さてIntel ARC A770を無事に装着して、電源を入れる前に、さらに(僕にとっては)悲報が一つある。それはIntelのiGPUを外部出力として利用できないということだ。NVIDIAのTelsa P40などは計算専用だから出力ポートなど持っておらず、僕はUEFI設定でiGPUをDisable –> Enable設定へ変更することによって、Telsa P40を計算専用デバイスとして利用することが出来た。
しかしIntel ARC A770の場合には、今のところDisableに設定変更するしかない。Ubuntuをインストールした後でIntel ARC A770用ドライバを導入したら、なぜか2560 x 1440画面 –> 1024 x 768画面となってしまった。Ubuntuの設定画面で見たら「不明なデバイス」と表示されていたので、A770用のIntel Iris Xe Graphicsドライバが何か悪さをしているのかもしれない。
構築内容
さて動作環境の整備が終わったら、いよいよ構築作業の開始となる。まずUbuntu 22.04をインストールすることになるが、これはアッサリと終わる。
お次はGPUドライバの導入なのだけれども、実はさっそく「やってしまった」
せっかく「iGPUとARC用ドライバはコチラ」とリンクを貼ってくれているのに、ついTelsa P40のクセでDC向けドライバであるdGPU側のリンクを叩いてしまった。その結果は… 「振り出しに戻る」である。
で、気を取り直してインストールを再開したけれども、これはアッサリと終わった。「\」と表示されているのは「続けて次行の処理を実行する」という意味なので、「\」が付いている部分は数行を一括コピーして、一気にコマンド処理を実行する。そうでないところは地道に一行ずつ実行する訳で、そこさえ指示通りに作業できれば問題ない。
無事にドライバのインストールが完了したかを、指示に従って確認する。
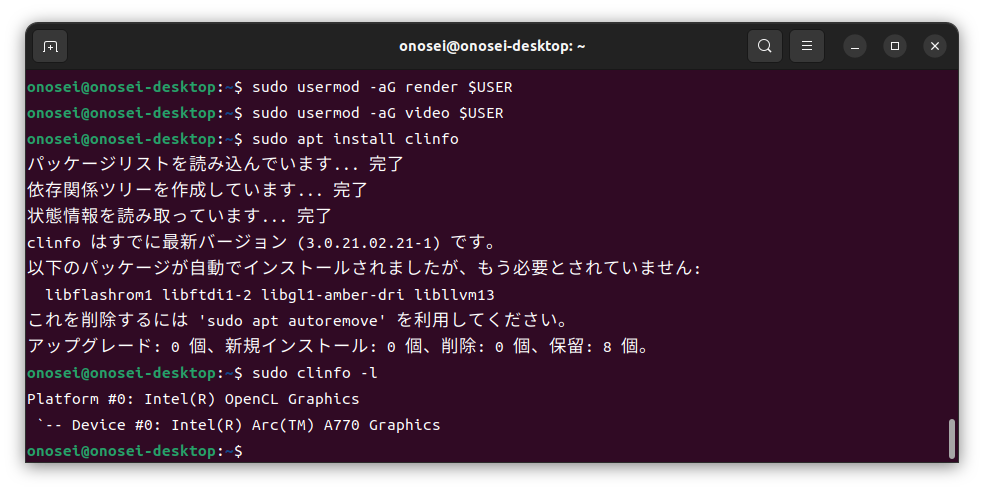
ドライバのインストールが無事に終わったら、次はoneAPIのインストールだ。今回はオンラインインストールを選択した。
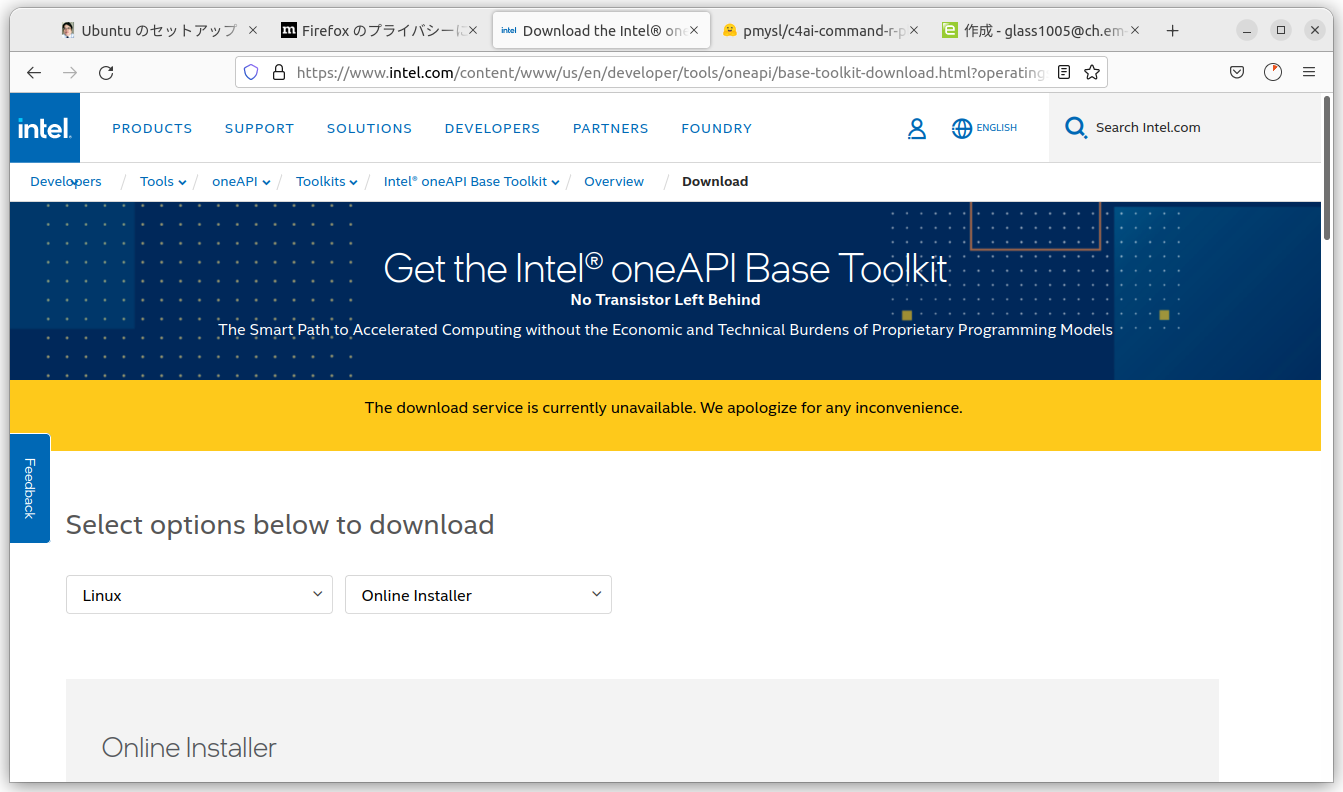
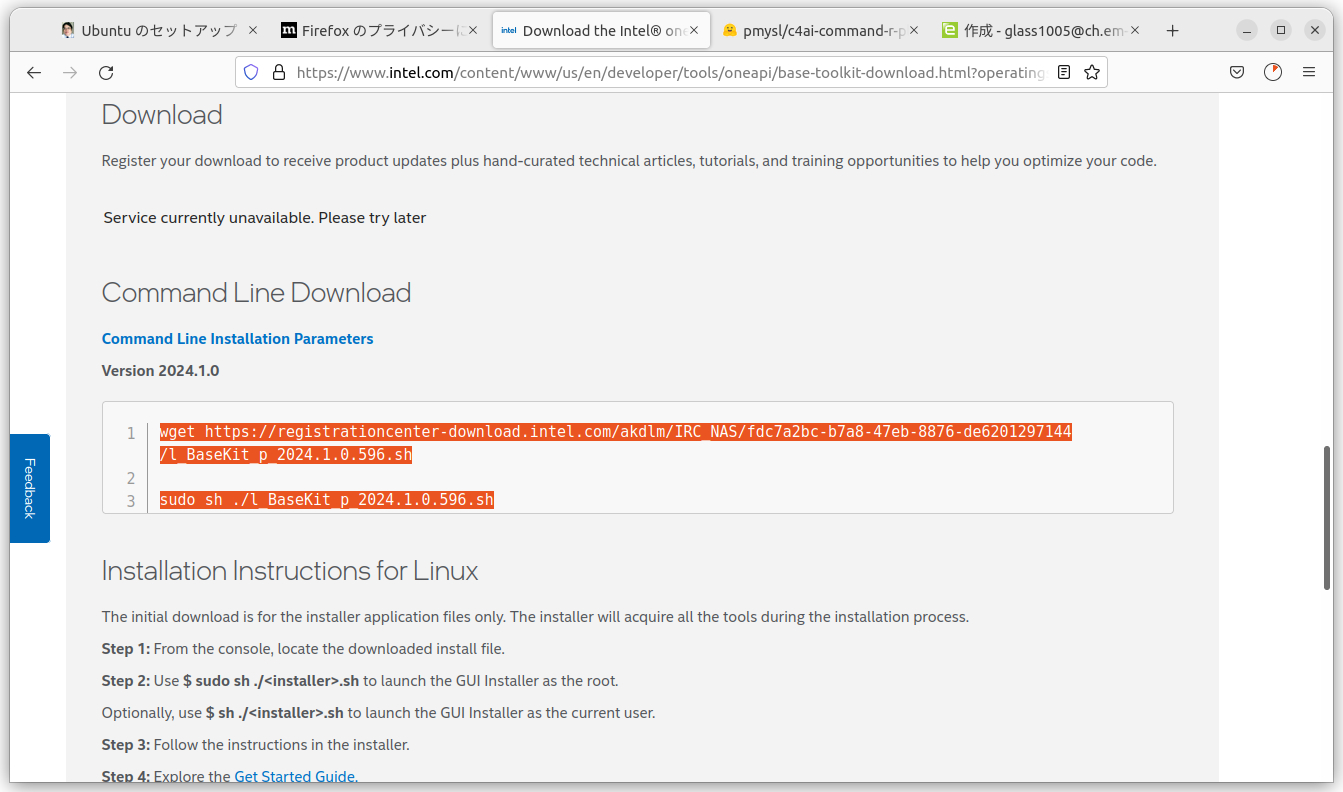
ページを下の方へスクロールして、コマンドが書かれてる部分をコピーして、端末画面(コンソール)に入力してやる。そうするとGUIベースのインストール画面が、自動的に起動される。ちなみに2024年1月にSwallo LLMを試した人は2024.0だったけれども、2024.05.26時点では2024.1.0となっている。
あとはライセンス内容を確認し、Recommendated Install (推奨インストール) を選択する。
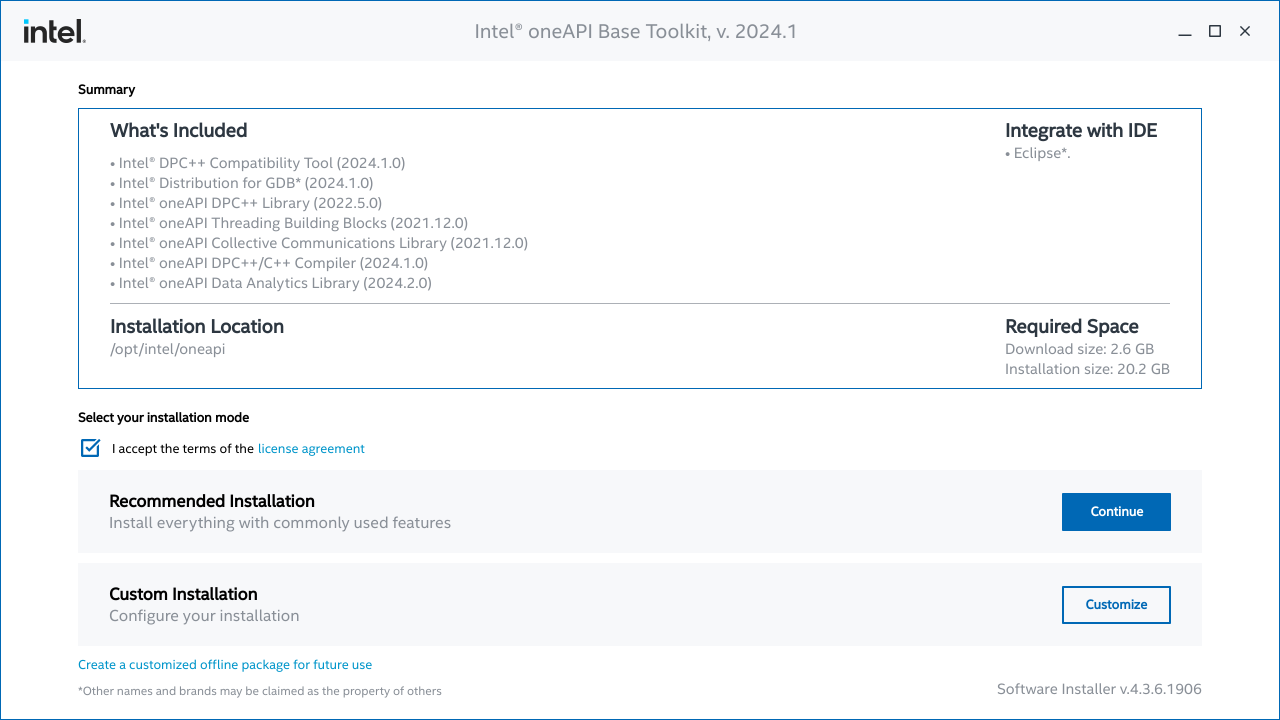
Eclips開発環境など使ったことはないので、最初から選択されているSkipでそのままインストール作業を継続する。
別にIntelに見られて困ることをする訳ではないので、情報提供にも同意した。これでoneAPIのインストールは終了である。終わった後は、別にNVIDIA系GPUを追加することもないので、「3. Verify installation and environment」へと進んでoneAPIインストール結果を確認する。
表示内容に次のような行が存在していたら、無事にインストール成功したと言えるだろう。
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26918]
無事にoneAPIがインストールできたことを確認したら、いよいよLlama.cppのインストールである。各サイト(ご本家も含む)で紹介されているのと同じく、gitコマンドでllama.cppをダウンロードしてからllama.cppディレクトリに移動し、手順に従ってコンパイル作業を実施する。
ちなみに今回も特に推奨されていなかったので、Linkedinの参考例と同じくFP32(推奨)のみを利用した。
以上で、インストールは完了。あとは推論(生成)処理を走らせるだけとなる。
実施結果
さて実施結果だけれども、4bit量子化版LLMのGGUFファイルは問題なく実行できた… と思う。「思う」というのは、ファイルが小さいからCPUのみとIntel GPUであるARC A770で実行した時の速度差を体感できなかったから。
どちらも、あっという間に終わってしまった。
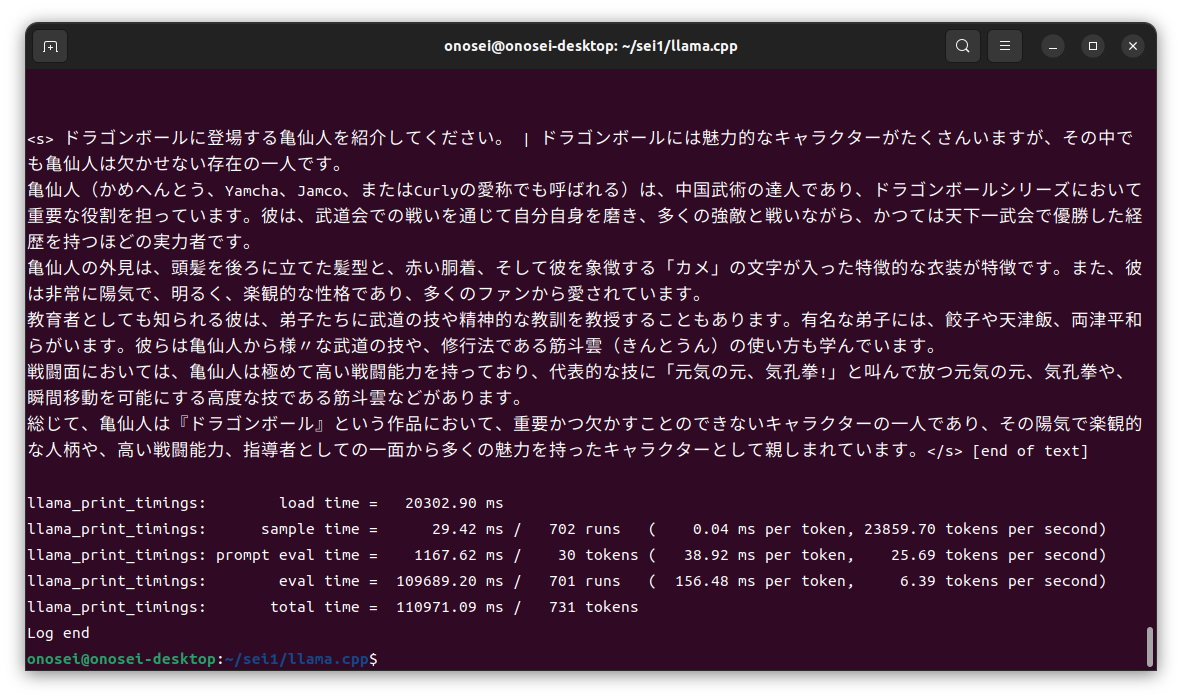
ZES_ENABLE_SYSMAN=1 ./build/bin/main -p “ドラゴンボールに登場する亀仙人を紹介してく ださい” -ngl 5 -mg 0 -m ./models/DataPilot-ArrowPro-7B-KUJIRA-Q4_K_M.gguf
なんでVRAMへのオフロードが5層(-ngl 5)の例を紹介しているかというと、最初は最終目的である4bit量子化版Command R+ 104B版 (約64GB) を動かそうとしたからだ。ただしそちらは残念ながら、ド素人な野良エンジニアには理解できないメッセージを吐いて異常終了してしまった。
なお上記の異常終了は、昨日経験したばかりだ。だから少しはネットやコミュニティで情報を集めたり、Windows版での挙動を確認しながら対応を進めたいと考えている。
しめくくり
とりあえず時間を確保できていないので、Intel GPUのARC 770でLlama.cppを動作させることだけはやってみた。自分的にはCommand R+方面を進めたいけれども、Pytorch方面のIntel GPU動向も把握しておく必要がある。
貧乏暇なしとは、このような状況を指すのだろうか。ともかく誰もテスト結果すら公開していないので、まずは簡単に試した結果だけでも公開しておく次第である。

ともかくIntelはCPUシェアがある状況で、Xeon SPを投入してきて推論(生成)方面では目の離せない存在である。引き続き、新しいおもちゃ(ARC A770)で各種の試行錯誤をしたいと考えている。
それでは今回は、この辺で。ではまた。
------
記事作成:小野谷静(オノセー)




